
Владельцы поисковых систем Гугл, Яндекс и прочих стараются держать алгоритмы работы и факторы ранжирования своих поисковиков в секрете, однако их основные программные средства давно уже определены.
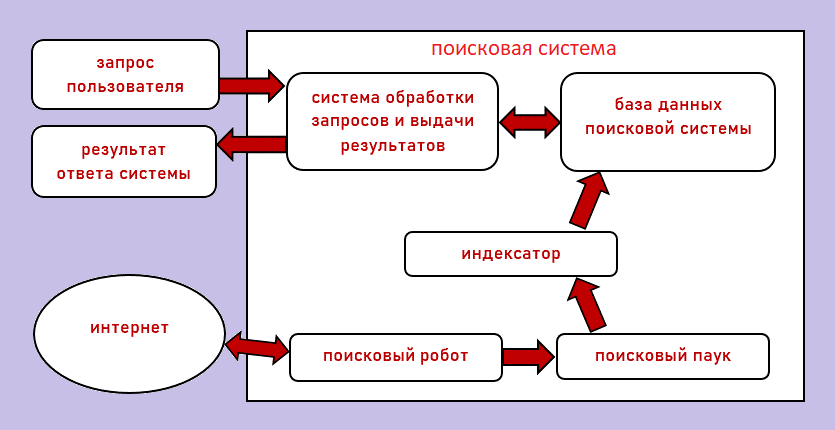
Все поисковики в общих чертах представляют собой следующий комплекс программ:
1) Поисковый робот (сканер, «червяк») — программа, предназначенная для нахождения на странице новых ссылок и занесение их в базу данных. Далее по найденным ссылкам будет переходить «паук» и обрабатывать их.
На языке программирования Java приложение «поисковый робот» может быть реализовано, например, с применением “извлекающего синтаксического анализатора” (StAX-анализатора).
Программа «Поисковый робот»

Как работает Поисковый робот?
Описание алгоритмов программы, если будет интересно для программистов на JAVA, Вы найдёте в книге – Кей Хорстманн, Гари Корнелл. JAVA. Том 2. на странице 162-165.
Вкратце расскажу, что создаётся метод, который парсит XML-документ (карта сайты в основном делают тоже в формате XML). В нём перебираются все слова на сравнение с элементом “a”, и если документ пустой, то выводится адрес консорциума World Wide Web (W3C). Если будет найден элемент “a”, который относится к тегу указания гиперссылки <a href>, то найденные ссылки выводятся списком в консоль.


2) Поисковый «паук» — программа, которая обрабатывает HTML-разметку интернет-страниц. «Паук» переходит по найденным роботом ссылкам на соответствующие страницы и сканирует их. Информация с веб-страницы скачивается и загружается в базу данных поисковика. Для реализации программы «поисковый паук» используются алгоритмы сопоставления с регулярными выражениями, потоковый синтаксический анализатор, DOM (англ. Document Object Model – объектная модель документа), анализатор и другие.
3) Индексатор (англ. Indexer, индексный робот) — это программа, проверяющая скачанные «пауком» страницы на соответствие каким-либо запросам, тем самым составляя уникальный индекс.
4) База данных — программа, предназначенная для хранения загруженных ссылок и содержимого веб-страниц.
В целом индексация сайта выполняется так:«паук» заходит на интернет-страницы по известным ему ссылкам, скачивает содержимое страниц и направляет его индексатору. Последний в свою очередь отбирает слова из загруженных списков и сортирует их в определённом порядке, присваивая соответствующий индекс.
5) Система обработки запросов и выдачи результатов — программа, которая получает введённый человеком запрос по поиску информации, затем направляет этот запрос в базу данных, и после обработки запроса выводит в браузере список найденных результатов.
Комплекс программ поисковых систем Интернета
Жизненный цикл поискового запроса в Яндексе представляется в таком виде:
– человек в строке поиска Яндекса набирает запрос;
– Яндекс сканирует по индексу свою базу и находит записи о заданных ключевых словах;
– из базы отбираются страницы с требуемыми ключами. Если в запрос входит не одно слово, а несколько, тогда поисковик сопоставляет по каждому слову списки ссылок и отбирает только те ссылки, индексы которых дублируются. В результате в отбор попадают те записи, на которых имеются одновременно все заданные в поисковом запросе слова;
– выполняется сортировка отобранных веб-страниц по релевантности к требуемому запросу и рейтингам сайтов, на которых эти страницы расположены;
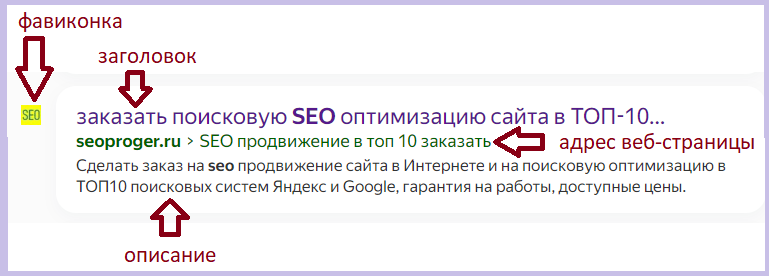
– ссылки на найденные интернет-страницы человек получает на странице выдачи результатов. Как правило, при выдаче отображаются сниппеты веб-страниц, которые включают заголовок, адрес и цитату из текста с требуемыми словами.
Сниппет веб-страницы в выдаче результатов
Но изначально поисковая машина не может начать работать самостоятельно, в неё нужно загрузить первоначальный список ссылок. Список ссылок веб-страниц обычно берётся из интернет-каталогов и загружается вручную. Далее «червяк» обрабатывает загруженные страницы и собирает с них новые ссылки, пополняя таким образом первоначальный список.
В настоящее время при создании сайта разработчики могут самостоятельно зарегистрировать его в поисковиках, тем самым открывая доступ для обработки соответствующей поисковой системе.
В начале следующего текстового блока следует сразу определиться с терминологией. На практике понятия «данные» и «информация» часто используются как синонимы. Однако в информатике они являются категорически разными понятиями. А именно:
Данные – неоцененные сведения о чем-либо, которые просто существуют на любом носителе (флешка, диск, бумага…).
Информация – это уже данные, которые были обработаны программой или человеком и их можно применять для принятия решений, в том числе управленческих.
Меру ценности (или цену) информации на страницах Интернета определить в денежном эквиваленте не так просто. Однако ценность информации на разных веб-страницах по определённой предметной области можно сравнить между собой. Так это и выполняется поисковиками.
Для проведения такого сравнения нужно вычислить уровень ценности необходимой информации таким способом, что уровень ценности будет равняться 100% в случае, если такие данные являются самыми ценными, либо равной 0% в случае, если они не имеют абсолютно никакой ценности (бесполезные), либо в диапазоне от 100% до 0% по сравнению с интернет-страницами со 100%-ной ценностью. Страницы с бесполезной (0%) ценностью поисковик не выводит на экран и даже может полностью блокировать при индексации из-за малополезного контента или избытка рекламы.
До того момента, как ценность содержания интернет-страниц будет определена, т.е. ранжирована в терминах поисковых систем, её показатель можно рассчитать в виде математического ожидания, в нашем случае, ценности информации.
А математическое ожидание случайной величины с одинаковой вероятностью каждого значения Pi, будет равно среднеарифметическому значению <P> всех имеющихся в выборке значений по формуле ниже.
Формула определения меры ценности информации до обработки поисковой системой
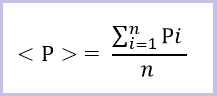
<P> – среднеарифметическое значение,
Pi – значение i-й выборки,
i – порядковый номер,
n – общее количество значений в выборке.
Подставим в формулу общее количество значений (n = 101) и все порядковые номера i-той выборки (от 1 до 101), получим следующее:
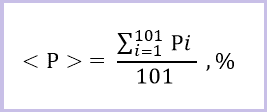
Возможно у кого то возникнет вопрос, почему количество значений в выборке n = 101?
– Ответ такой: значение “0” считается 1-м номером, а значение “100” в итоге будет 101-м номером.
Найдём значение <P> по указанной выше формуле, подставив известные значения Pi (от 0% до 100%).
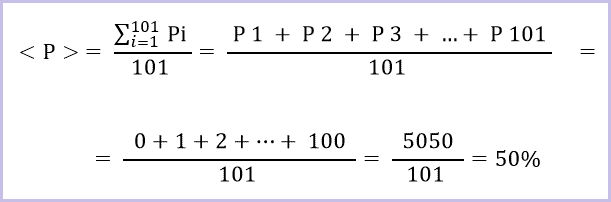
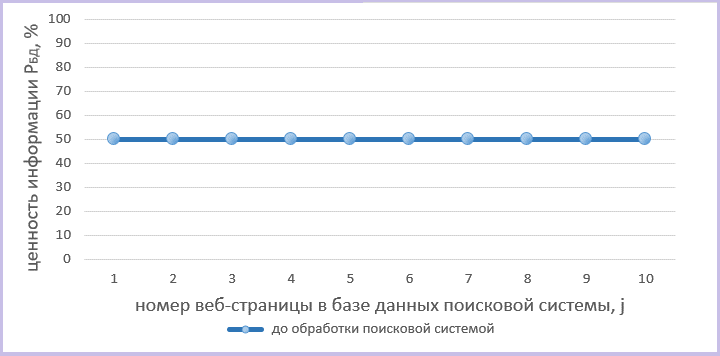
Получим, что математическое ожидание ценности информации j-той интернет-страницы <P>БДj до ранжирования поисковиком составляет 50%. Отобразим это на диаграмме.
Ценность информации веб-страниц до ранжирования в поисковой выдаче, %
Рассмотрим типичный повседневный случай о том, как определиться и выбрать интернет-страницу с самой ценной информацией из списка из имеющихся 10-ти страниц в Яндексе. Как раз такое количество источников по умолчанию, т.е. без самостоятельной настройки, Яндекс предоставляет на выбор пользователю в ответ на его запрос.
Отметим, что человек, который должен сделать выбор определенной информации из массы ему неизвестной становится лицом, принимающим решение в условиях неопределенности.
Свести к минимуму возникшую неопределённость в выборе информации ему поможет поисковая машина.
Так на определённый запрос человека содержимое каждой j-той веб-страницы в индексе Яндекса <P>БДj обрабатываются специальной формулой ранжирования, которая является коммерческой тайной владельца.
Ценность информации PПСk некоторой j-той веб-страницы после ранжирования поисковиком представим формулой ниже.
Определение ценности информации после обработки поисковиком
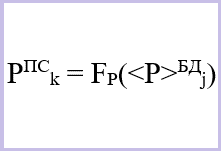
PПСk – ценность информации k-той страницы после ранжирования поисковой системой (ПС),
k – позиция веб-страницы в выдаче результатов поиска,
FР(<P>БДj) – функция ранжирования,
<P>БДj – ценность информации страницы в базе данных (БД) до ранжирования системой,
j – номер страницы в выборке.
В результате веб-страницы с ключевыми словами сортируются по наибольшей релевантности запросу человека с помощью функции ранжирования FР(<P>БДj) и размещаются по k-тым позициям в выдаче результатов.
На первой позиции (k=1) выдачи Яндекс выводит самую релевантную с её точки зрения веб-страницу из всех, которые находятся в индексе. Её ценность равна 100%.
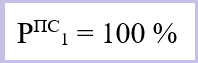
Ценность информации веб-страницы на 1-й позиции выдачи результатов (с точки зрения выбранной поисковой машины).
1 позиция поисковой выдачи
Затем функция убывает прямо пропорционально, размещая остальные страницы по следующим позициям, т.е. ценность информации этих страниц становится всё ниже и ниже.
Ценность информации интернет-страниц после ранжирования поисковой выдачи

Но нельзя считать, в действительности ценность информации ресурсов установлена абсолютно верно для 1-й позиции и следующих за ней.
Функция ранжирования веб-страниц линейно убывает, но не показывает насколько одна страница лучше, чем следующая за ней. Показываются лишь результаты ранжирования, в которых страницы с менее ценной информацией следуют друг за другом.
А если сделать одинаковый запрос в разных поисковых сервисах, в первую очередь в Гугле и Яндексе, то мы получим неодинаковые результаты по занимаемым веб-страницами позициям. Это связано с тем, что каждый поисковая машина имеет свою собственную формулу ранжирования.
Если нужно найти самую ценную веб-страницу, то следует сделать запрос разных системах, сопоставить полученные результаты и выбрать из них те, которые имеют самые высокие результаты в различных поисковиках.
При этом на в выдаче результатов, как правило, на первых 3-4 позициях может располагаться контекстная поисковая реклама – это проплаченные рекламные объявления, которые будут показываться автоматически. Контекстную поисковую рекламу можно легко отличить, поскольку она будет отмечена надписью «Реклама».
При этом на в выдаче результатов, как правило, на первых 3-4 позициях может располагаться контекстная поисковая реклама – это проплаченные рекламные объявления, которые будут показываться автоматически. Контекстную поисковую рекламу можно легко отличить, поскольку она будет отмечена надписью «Реклама».
Однако большинство пользователей Интернета отдают предпочтение естественным результатам отбора, что вполне оправдано. Ввиду того, что за деньги разрекламировать можно всё-что угодно.
Конечно позиции веб-страниц на первых местах в поисковой выдаче могут быть искусственно завышены, как правило, SEO-специалистами с помощью проектирования seo продвижения и методов поисковой оптимизации.
Однако, если страница – бесполезная, то и продвинуть её на первые места выдачи результатов будет никак невозможно.
Так работают поисковые системы Яндекс и Гугл в Интернете!
Данная статья “РОЛЬ ПОИСКОВЫХ СИСТЕМ В ПОВЫШЕНИИ РЕЛЕВАНТНОСТИ ВЫДАВАЕМОЙ
ИНФОРМАЦИИ В СЕТИ ИНТЕРНЕТ” была опубликована в научном журнале на стр. 59-64 (читать).
Автор статьи – Верещагин Владислав Васильевич,
магистр кафедры прикладной информатики и математики